Understanding Git under the hood
How Git internals work to organize data and history

9 minutes read
Most developers are familiar with version control system and git is de facto choice for most cases. This article is actually to introduce how git works, and this will enable for developers to understand git better.
Git is distributed version control where history of file and directory changes are stored such that developers can travel through time to gather how all the changes happened. Initially git was created by Linux creator to manage Linux kernel development when having multiple open-source developer.
In Linux manual pages (man git), Git is identified as “the stupid content tracker”. Through this article you can identify why git is called as such.
Git ‘Porcelain’ & ‘Plumbing’ Commands
Most of the commands used in developer work flows are known as “porcelain commands”. But these commands are constructed through low level commands known as “plumbing commands”. Lets take an example:
- Porcelain Commands →
git add,git commit,git push,git pull,git branch,git checkout,git tag,git merge,git rebase& more… - Plumbing Commands →
git cat-file,git has-object,git count-objects
Understanding Hashes & SHA-1
Even though y’all should be familiar with hashes, it is required to summarize a bit to make this article is complete. Simply hash values are generated for some input through a cryptographic function. Git uses SHA-1 algorithm.
This simple function return hashes as calculated in git. It executes git hash-object on stdin input.
echo 'aaa' | git hash-object --stdin
→ 72943a16fb2c8f38f9dde202b7a70ccc19c52f34
Similarly hash values include:
"aaa" → 72943a16fb2c8f38f9dde202b7a70ccc19c52f34
"aab" → 6f27bcf7c99320f97e935dac870033e697bc5b11
"bbb" → f761ec192d9f0dca3329044b96ebdb12839dbff6
- Hash values always generate 40-digit hexadecimal number from any input
- Same input will always generate same hash value
- Slight difference to input will completely change hash value
- Input can’t be identified from hash values, & hash function is not reversible
- Hash values are not indefinite as its limited to 40 digits. But probability of two inputs generating same hash is almost zero, making hashes unique.
Git Directory
Lets initiate empty git repository using git init and you will see that hidden directory of .git is created in that location. Lets check inside .git/:
branches/
config
description
HEAD
hooks/
info/
objects/
refs/
Most of these inner directories such as branches/ or objects/ will be empty since this was just initiated. This .git will have all the details of git related files, directories and other information and will be discussed later.
Git Object Database
Let’s check how hash values are stored in git database in .git. To write it to git database, we can use earlier command for calculate hash but with -w.
echo 'aaa' | git hash-object --stdin -w
Here it is expected that aaa is stored in git object database somehow.
Git object database is actually key-value map that is persisted. Hence for any element hash value of content is will be key, and value will be content.
Here 72943a16fb2c8f38f9dde202b7a70ccc19c52f34 will be key and value will be aaa. As this element was written lets check it placed in .git/objects. There will be a directory with first two elements in hash 72, and within it a file with rest of hash value: 943a16fb2c8f38f9dde202b7a70ccc19c52f34.
user@ubuntu:~/git-internals/.git/objects/72$ ls
943a16fb2c8f38f9dde202b7a70ccc19c52f34
Content of this file is encrypted, and can’t be read directly. Hence there is a function that can be used to read values from git database returning aaa.
git cat-file 72943a16fb2c8f38f9dde202b7a70ccc19c52f34 -p
This showed how data can be written and read from git objects database and how its organized as key-value map, and divided by hash values to increase performance.
Git Objects
Git tracks all content and is stored in git database as objects. Types include:
- Blob → File content stored as raw binary data.
- Trees → Directory content stored.
- Commits → Commit content stored.
- Annotated Tags → Tag content stored.
Any of these content can be used calculate hash value, and content will be stored in objects database where hash in the key. Git doesn’t differentiate between these types and all stored equally in .git/objects. Its better to learn these types through examples.
Git Objects for Commits, Files & Directories
To clearly understand Git objects and its databases, lets create a file & commit into git repository.
The quarterly results look great!
- Revenue was off the chart.
- Profits were higher than ever.
Everything is going according to plan.
Through git log identify hash value for the last commit and then read this value from object database: git cat-file 239d1a0 -p. (7 digits can be used to identify git objects on most projects and known as short SHA)
tree 37057b2e8a9041ef88b805a5b7c4e0e668a03be4
author Thomas Shelby <user@gmail.com> 1588048341 +0530
committer Thomas Shelby <user@gmail.com> 1588048341 +0530
Add a file
This git object for commit contains author, time, message & tree. Here tree value seems to be another hash value, and it refers to state of project at time of commit. Lets check for git object for tree→ git cat-file 37057b2 -p.
100644 blob 72943a16fb2c8f38f9dde202b7a70ccc19c52f34 a.txt
This refers to say that the project has only blob (a file not a directory) named a.txt in base directory. So content of this file can be read from hash value.
aaa
This will return expected content of a.txt. Here from commit we were able construct entire content of directory by navigating from tree & blob objects. Hence it should be seen that from .git directory have all the information as git objects to construct working directory from a commit.
Lets check for git object database after this initial commit: tree .git/objects
.git/objects/
├── 23
│ └── 9d1a0f75b596d7d67e23721f11066abf144982
├── 37
│ └── 057b2e8a9041ef88b805a5b7c4e0e668a03be4
├── 72
│ └── 943a16fb2c8f38f9dde202b7a70ccc19c52f34
├── info
└── pack
This has all the 3 objects referring to commit, tree and blob git objects. Also git count-objects can be used to identify number of git objects.
Adding Sequential Commits, & Nested Directories / Files
This just had one file, and no directories. Lets add more blobs & trees to give clearly understanding of how files & directories are stored in object database.
$ mkdir files
$ echo "aaa" >> files/aaa.txt
$ echo "bbb" >> files/bbb.txt
$ git add .
$ git commit -m "Add files"
$ git log
It is intentional that aaa content is also added for the new file. Lets check upon commit content by reading that git object → git cat-file 5c45ebb -p.
tree 21e6981939eae6277ad2128753e2984b552868cf
parent 239d1a0f75b596d7d67e23721f11066abf144982
Important changes include parent attribute that refers to parent commit. and then observe that tree has changed since files and directories changed. Lets go one by one and check content of trees & blobs to build files & directories.
100644 blob 72943a16fb2c8f38f9dde202b7a70ccc19c52f34 a.txt
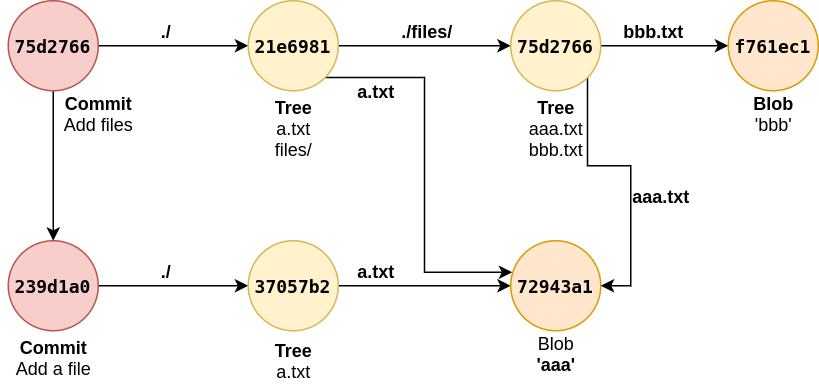
040000 tree 75d27669a0c4e9dd702c71c6ac3307d533493ba5 files
Git object for a.txt remains same as content remains same. But within the parent tree object, there is another tree which represents that its a directory. When checking content of this nested tree: git cat-file 75d2766 -p
100644 blob 72943a16fb2c8f38f9dde202b7a70ccc19c52f34 aaa.txt
100644 blob f761ec192d9f0dca3329044b96ebdb12839dbff6 bbb.txt
If blobs are checked it will have expected content. Note that here aaa.txt will have same object of a.txt cause the content of the files are same containing aaa. However file name change didn’t effect this as it was not stored in blob itself but rather it was stored in its containing tree.
Git Object Model
It can been seen how git reused common blob containing aaa between two commits. Only 7 objects
.git/objects/
├── 21
│ └── e6981939eae6277ad2128753e2984b552868cf
├── 23
│ └── 9d1a0f75b596d7d67e23721f11066abf144982
├── 37
│ └── 057b2e8a9041ef88b805a5b7c4e0e668a03be4
├── 5c
│ └── 45ebb2052428ce037e2fbf760cb0ec9a18f6e2
├── 72
│ └── 943a16fb2c8f38f9dde202b7a70ccc19c52f34
├── 75
│ └── d27669a0c4e9dd702c71c6ac3307d533493ba5
├── f7
│ └── 61ec192d9f0dca3329044b96ebdb12839dbff6
Interpret working directory from commit
This currently have two commits, and user can checkout to either of these commits. For either of the commits, its perspective of files and directories might differ. For a commit it will ignore connected commits, and build up files and directories using trees and blobs it is connected to Here it will show how its seen by two commits

Edit existing files
Previous commit was able to show how newly added directories or files are represented. In this commit it will show how file edit is reflected in git object model: edit a.txt in root directory content to aab.
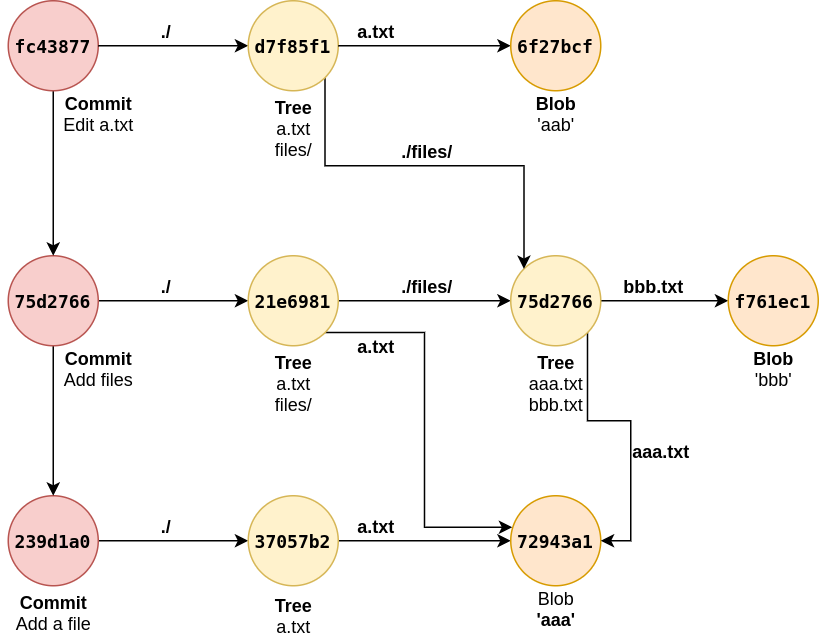
To wrap up about git objects these simply refers as follows:
- Tree → Represents directory. Contain file structure containing trees/blobs
- Blob → Represents file. Contains encrypted file content.
- Commit →Represents commit. Contains author & refereed parent tree
- Tags → Represents annotated tags. Contains refereed commit.
Git Branches
By default git creates default master branch. Hence this reference is to be stored somewhere with .git. Its actually stored in .git/refs/heads/master, and not encrypted file thereby can be read as cat .git/refs/heads/master. This just contains hash value of last commit done. Thereby git branches are just references to git commit hash value.
Lets try to add branch and commit to check how references are kept.
$ git checkout -b branch1 # create branch and switch to it
$ cat .git/refs/heads/branch1 # refers to same commit as master
$ nano a.txt # edit content of a.txt
$ echo "ccc" >> c.txt # add new file of c.txt
$ git add .
$ git commit -m "branch1"
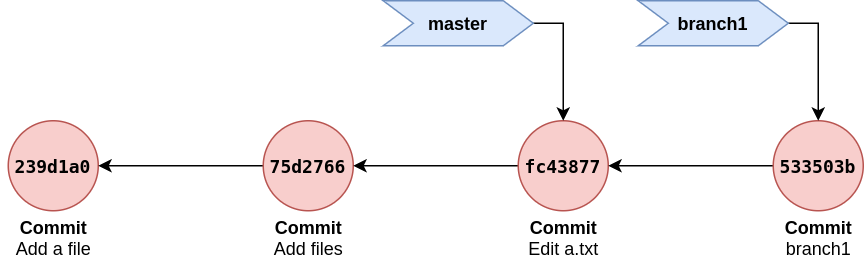
Verify that branch1 reference modified and is now referencing new commit. Current branch is stored in less .git/HEAD as refs/heads/branch1.
Let’s checkout back to master branch using git checkout master and notice that this will change current branch in HEAD file as well as construct files and directories according to that commit. Hence notice that c.txt that was added in new commit, gets removed.
$ git checkout master # create branch and switch to it
$ nano a.txt # edit content of a.txt
$ git add .
$ git commit -m "master"
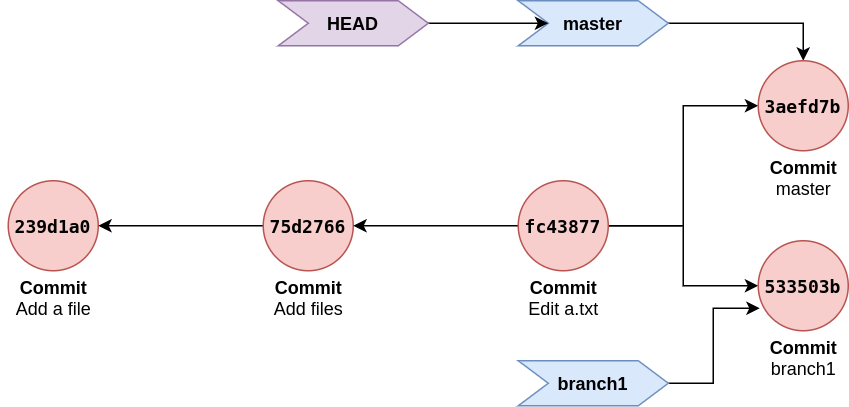
Since it was already switched to master as current branch, it will not have to update HEAD at every commit. But at every commit, master branch reference to commit is updated to new commit.
To wrap up thing up with branches:
- Branch → Is a reference to commit
- HEAD → Is a reference to branch. (Can refer a commit directly in case of detached head where checkout to a commit.
git checkout commit_id)
Git Garbage Collector
As seen git branches just refers commit id, hence lets alter git files to make a commit without any references. (Note: this is hack done for demo purpose.)
cat .git/refs/heads/master > .git/refs/heads/branch1
This replaces branch1 commit reference with master commit reference.
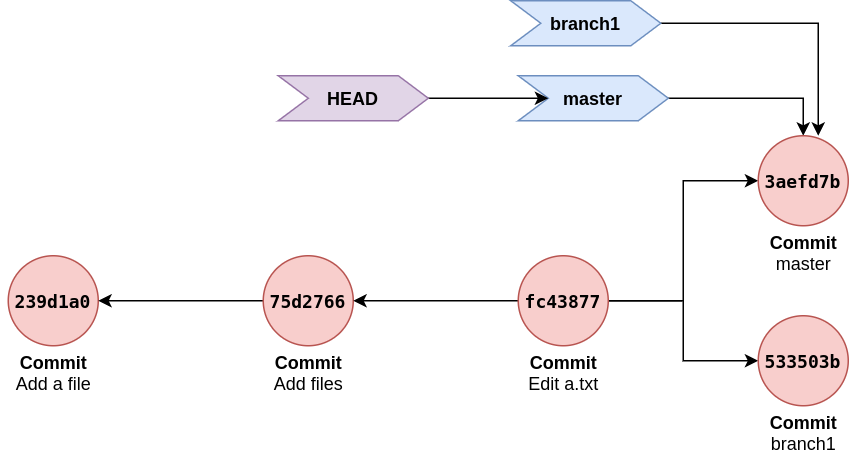
Here both branches refers same commit in 3aefd7b & commit in 533503b is not referred by branch, another commit or tag.
After some time these git objects without any reference will be garbage collected and deleted.
As the definition suggested by “the stupid content tracker” it can seen that git keeps track of files and directories at each time framework of project. It has the capability of fully constructing working directory for given time. Hence it is fair to say that git tracks content.
This is brief introduction of how git works under the hood to manage high level commands for end user. This aims to shed some light on how git manages files, commits and branches. Proper understanding of how git works will allow grasp of advanced git concepts too.